
共起ネットワークとは、SNS投稿やWebサイト、アンケート、書籍/論文、歌詞などの「文章」に含まれる「単語間の共通性」を見出し、図で表現する方法です。
この共起ネットワーク、テキストにおける単語同士のつながりを可視化し、視覚的に理解を促せるため、テキストマイニングの手法として非常に人気が高いです。
この記事では、「青空文庫」に掲載されている小説を題材とし、KH CoderやPythonを使って共起ネットワークを作る方法を解説します。加えて、どういったことが読み取れるのか、どんな示唆出しができるのか、など共起ネットワークの解釈方法についてもお伝えします。
KH Coderは、無料で使えるテキストマイニングツール(主にWindows端末向け)です。Pythonは、無料で使える統計解析や機械学習に用いるプログラミング言語のひとつ。テキストマイニングのためのライブラリも完備しています。
KHCoder 初心者は必読!
開発者による公式入門書

動かして学ぶ! はじめてのテキストマイニング: フリー・ソフトウェアを用いた自由記述の計量テキスト分析 KH Coder オフィシャルブック II (KH Coder OFFICIAL BOOK 2)
KHCoderを使いこなしたい!
中上級者を目指す方はこちらも

社会調査のための計量テキスト分析―内容分析の継承と発展を目指して【第2版】 KH Coder オフィシャルブック 単行本 – 2020/4/6
- 本記事のゴール
- 共起ネットワークの概要と重要な指標・処理
- 共起ネットワークとは
- Jaccard係数(ジャッカード係数)とは
- 形態素解析・分かち書き
- 本記事で共起ネットワーク作成に利用するデータについて
- KH Coderによる共起ネットワーク描画
- Pythonによる共起ネットワーク描画
- 共起ネットワークを描くために必要なモジュールをインポートする
- 共起ネットワーク描画(サンプルコードあり)
- Pythonで描いた共起ネットワークとKH Coder版との違い
- アウトプットのチューニング
- コラム|MeCabによる複合語抽出と代替方法
- まとめ|KH CoderやPythonで共起ネットワーク描画にチャレンジしてみよう
本記事のゴール
本記事のゴールは、以下の2つです。
・KH CoderとPythonで共起ネットワークを作れるようになる
・共起ネットワークを解釈できるようになる

ゴール1のイメージ|KH CoderとPythonで共起ネットワークを作れるようになる
各手法による共起ネットワーク作成の手順を丁寧に解説します。テキストマイニングの概要を知りたい方は、以下の記事も併せてご覧ください。

たとえば、KH Coderでは以下のようなアウトプットを作れるようになります。
こちらは、夏目漱石の『こころ』をベースにから作成された共起ネットワークの例です。
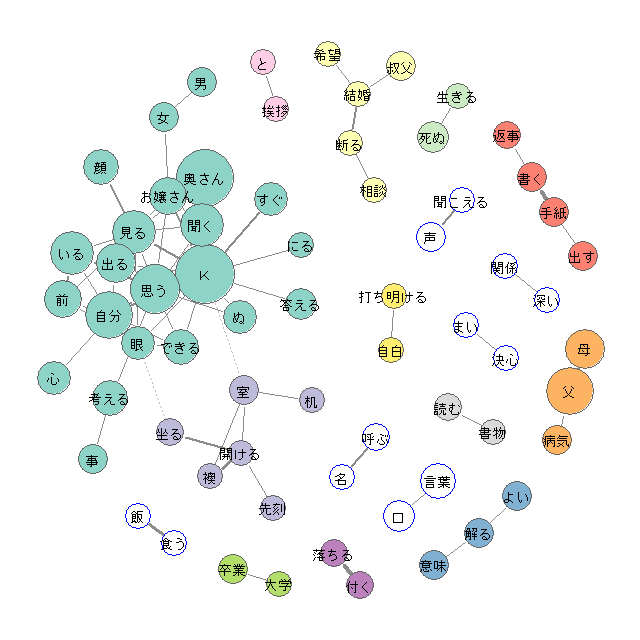
ゴール2のイメージ|共起ネットワークを解釈できるようになる
ゴール1のイメージで示された共起ネットワーク、見た目にはきれいで何となく分かったような気になりやすいのが玉に瑕です。
この「共起ネットワークを言語化できるようになること」がもうひとつのゴールです。
以下に言語化の例を示します。
- 一番他のワードと頻度が高く出現するワードは”K”である(”K”は小説内に登場する友人の呼び名) ※一番大きな円
- ”聞こえる”と”声”の関連が強いため、聞こえるモノの多くは声である ※太い線
- ”食う”と”飯”の関連が強いため、食うモノの多くは飯である ※太い線
- ”書く”と”手紙”の関連が強いため、書くモノの多くは手紙である ※太い線
- "K"と”見る”と”顔”の関連が強いため、Kが見るモノの多くは顔である ※太い線
- ”K”と”自分”と”思う”の関連が強いため、Kと自分は”思う”ことが多い
共起ネットワークの概要と重要な指標・処理
共起ネットワークとは
共起ネットワークは単語間の関係性を視覚的に表現します。
この共起ネットワークに使う値としては、Jaccard係数(同時登場数による類似度)やCos類似度(ベクトルを使って向きが近い:1に近ければ類似度が高いと判定する)などがあります。今回はシンプルで分かりやすいJaccard係数をベースに解説します。
また、文章をそのまま扱うと、「単語が文中に何回出現したのか?」などの計算が大変です。そのため、テキストマイニングにおいては分かち書きという処理を行います。
Jaccard係数と分かち書きは、共起ネットワーク描出においてとても大切な考え方なので、まずはこれらを解説します。
Jaccard係数(ジャッカード係数)とは
その名の通り、Jaccardさんが考案した計数です。単語などのサンプルセット同士の類似度(距離)を測るための指標です。
テキストマイニングにおけるJaccard係数の算出は、概念を理解できれば決して難しくありません。また、KH Coderにおいては、今回取り上げている「共起ネットワーク」のみならず「階層的クラスター分析」や「多次元尺度構成法」においても使用されているので、概念理解はとても有用です。
さて、計算式に話を移します。Jaccard係数は以下の式で計算されます。
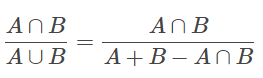
言葉で説明すると、「AかつB」を「AまたはB」の出現数で割る、と言えます。
「AまたはB」は、Aの出現数とBの出現数を足し、AとBの同時出現(二重計上)を引いて求める。
Jaccard係数の計算例
もう少しかみ砕くと、「単語Aと単語Bが文章に登場する際に、どの程度同時に登場するか?」を示します。
例えば、「私(A)」が80の文書に登場、「見る(B)」が100の文書に登場、「私(A)」と「見る(B)」が同時に20の文書で登場したとします。この場合の Jaccard係数は以下のように計算されます。
A∧B: 20 / (A: 80 + B: 100 ー A∧B: 20)
= 20 / 160
=0.25Jaccard 係数が大きいほど、同時登場が多い単語の組み合わせになるため、その二つの語は「類似している」「近い」と判断されるのです。
文章の中で”私”、”見る”という単語が同時に出現する事が多いと、”私”と”見る”の円がそれぞれ描かれ、円同士が線でつながれます。
形態素解析・分かち書き
テキストマイニングにおける形態素解析・分かち書きとは、文章を単語に分解することです。
例えば、以下の文章。
毎日、私は朝食として牛乳とパンを食べてから、出社します。
これを分かち書きすると、以下のように分解されます。
毎日 、 私 は 朝食 として 牛乳 と パン を 食べて から 、 出社 します 。
このように単語を品詞に分解すると、データとして扱いやすくなります。扱いやすくなる=計算がやりやすくなると考えて大丈夫です。
この分かち書き、手動でやるのは骨が折れますが、KH Coder や Python(MeCabなどのライブラリを利用)を使うと簡単に実行できます。
本記事で共起ネットワーク作成に利用するデータについて
自分で共起ネットワークを作ると感覚がつかめます。そのためにはテスト用のテキストデータが必要です。
テキストデータは、たとえばTwitterにAPI接続して投稿データをスクレイピングするのも一手です(実務においてSNS分析をおこなう場合などに使います)。しかし、まったく別の知識が必要になるので、今回はインターネット上のテキストデータをダウンロードして使います。
テスト用に使うおすすめデータは「著作権の消滅した作品」と「自由に読んでもらってかまわない作品」がまとまっている青空文庫です。
今回は、青空文庫から、芥川 竜之介の『羅生門』をダウンロードし、分析に供します。
青空文庫からテキストデータをダウンロードする
青空文庫では、作品名、あるいは作者で作品を検索できます。たとえば、羅生門で検索すると、以下のページが表示されます。

このページ下部の「ファイルのダウンロード」で、ファイル名(リンク)をクリックすると、作品のテキスト(圧縮ファイル)を取得できます。

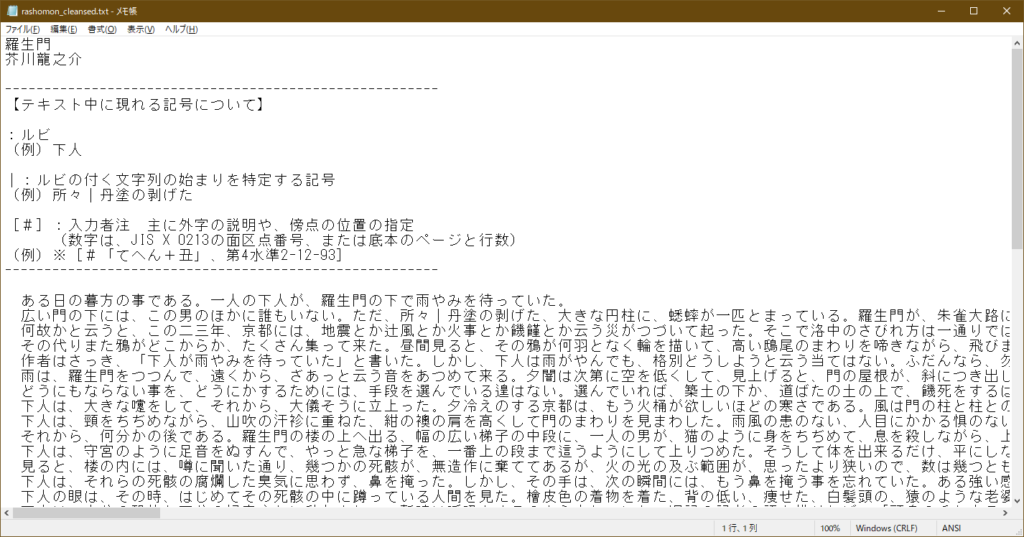
圧縮ファイルを解凍し、テキストエディタでデータを開くと以下のようになります。

ダウンロードしたデータをクレンジングする
このままでは、ルビが集計されるなどの問題があるので、ごく簡単なデータクレンジングを実行します。
ルビの削除は、正規表現を扱えるテキストエディタで正規表現:《[^》]*》で検索し、削除するだけです。
削除すると以下のデータに変わります。《と》で括られていた部分がなくなったのが分かりますでしょうか。
この他に[#と]で囲われた注も、正規表現:[#[^》]*]で検索し、削除します。最後に、テキストファイルの上部と下部にあった余分な情報を消すと、仕上がります。
このデータの文字コードはSJISからUTF-8 BOM有に変更すると、Pythonで扱いやすくなります。
なお、今回お示しした処理は青空文庫特有のものです。データソースによって要否や重経度、必要な処理が異なる点にご留意ください。
(参考)KH Coderにはサンプルデータがあらかじめ準備されている
KH Coderをダウンロードいただくと「C:\khcoder3\tutorial_jp」のフォルダに、夏目漱石の”こころ”のxls(kokoro.xls)が含まれています。
そちらを使うと、KH Coderの公式サイトで示されているチュートリアルと同じ分析ができ、理解が深まりますよ。
KH Coderによる共起ネットワーク描画
データの準備ができたので、KHCoderで共起ネットワークを作っていきましょう。
KH Coderのセットアップ
KHCoderの公式サイトの「ダウンロードと使い方」にあるダウンロードのリンクをクリックしてください。
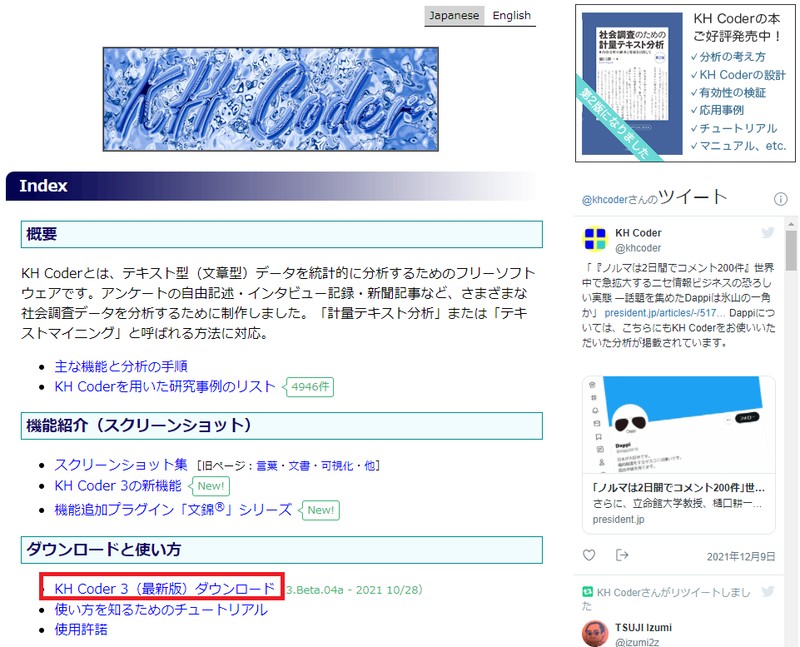
その後、フリー版のリンクからEXEファイルをダウンロードください。
(600MB以上のファイルなので、ダウンロードに多少時間かかります)
ダウンロードしたファイルをダブルクリックして実行ください。以下のように解凍のウィンドウが立ち上がるため、Unzipを実行ください。
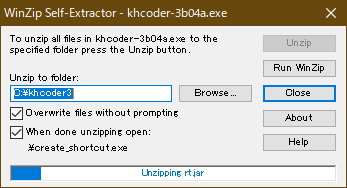
これで「C:\khcoder3」というフォルダにファイルが展開されます。
KH Coderでのテキストデータ読み込み
KH Coderは「C:\khcoder3\kh_coder.exe」をダブルクリックすると起動します。
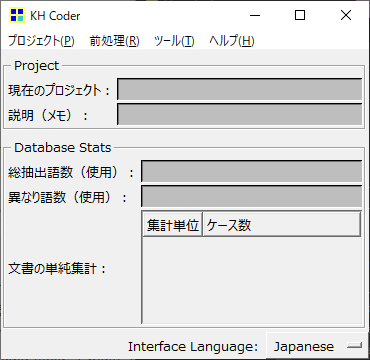
まずは上部メニューで [プロジェクト]-[新規] を選択します。
すると、「新規プロジェクト」のウィンドウが立ち上がります。

参照ボタンを押下して、分析するファイル(rashomon.txt)をセットすると、初期表示されるウィンドウに戻ります。
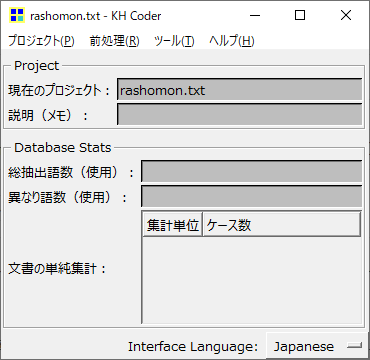
次に、上部メニューで [前処理]-[前処理の実行] を選びます。
そうすると以下のウィンドウが立ち上がるので、そのままOKを選択します。
処理が終わると以下のような処理時間が記載されたウィンドウが表示されます。
共起ネットワーク描画
前処理が終わりましたので共起ネットワークを表示します。
上部メニューで [ツール]-[抽出語]-[共起ネットワーク] を選びます。
そうすると以下のウィンドウが立ち上がるので、そのままOKを選択します。
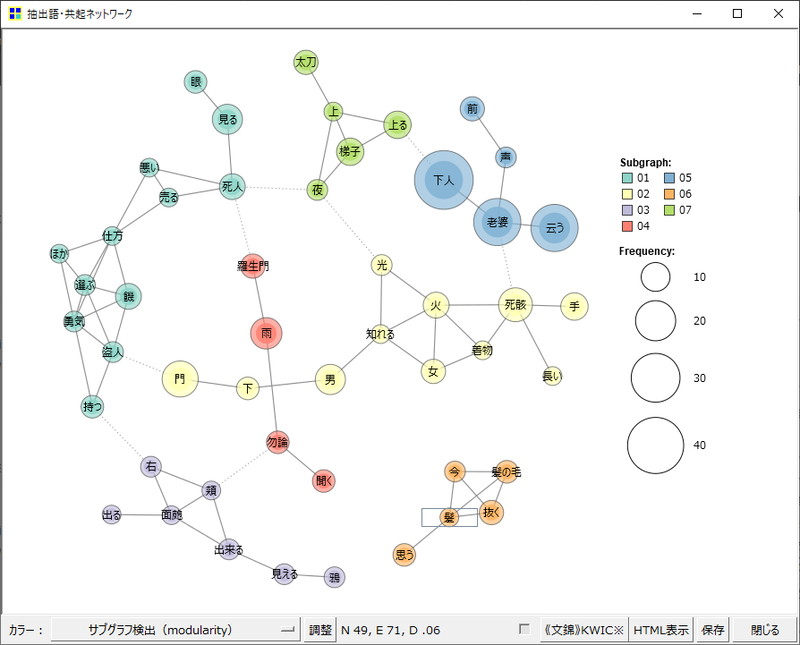
そうすると、以下のように共起ネットワークが作成されます。
より厳密に分析する場合は品詞の取捨選択や、単語のまとまりの指定(例:「焼肉定食」という文字列は「焼肉」と「定食」に分かち書きしない等)が必要です。今回はわかりやすさのために、詳細のステップは割愛しています。
KH Coderで描いた共起ネットワークの見方、考察・解釈方法
作成した共起ネットワークは7つのサブグラフで構成されています(色分けされています)。
円の大きさは単語の出現頻度で、線は一緒に登場する単語を結んでいます。
このことから、この共起ネットワークで以下のことが言えます。
- 01:死人を見たり、死人の傍で見たりするシーンが多そうだ
- 02:門と下と男が一緒に登場するので、門の下に男がいそうだ
- 03:面皰が右の頬にできたようだ
- 04:タイトルにもある羅生門は雨と一緒に登場することが多い
- 05:下人が老婆と一緒に登場し、何かを云うことが多そうだ
- 06:髪の毛を抜く話題が出ている
- 07:梯子を上るシーンも多そうだ
ポイントとしては、最も大きな円はどの単語の円か、各サブグラフで頻度の高い(大きい)ワードはどの単語と一緒に登場しているか(直接の線がつながっているか)です。
Pythonによる共起ネットワーク描画
次は、Pythonで共起ネットワークを作ります。
共起ネットワークを描くために必要なモジュールをインポートする
以下のライブラリを使って共起ネットワークを描きます。必要なものを予めpip installしてください。
なお、プログラムの中でノード間の重なりを上手くなくすため、GraphvizというSWを利用しております。
Graphvizはこちらを参考にインストールをお願いします。
stable版は2021年12月現在ありません。最新版を入れて動作確認してください
# 必要なモジュールのインポート
from pathlib import Path
import collections
import MeCab
import neologdn
import unicodedata
import networkx as nx
import matplotlib.pyplot as plt
from itertools import combinations, dropwhile
from collections import Counter, OrderedDict
import numpy as np
from networkx.drawing import nx_agraph
共起ネットワーク描画(サンプルコードあり)
KH Coderのインプットにした文章をテキストを指定し、分かち書きの実行からJaccard係数の計算、共起ネットワーク描画までを行うサンプルプログラムを掲載します(dataフォルダにあるrashomon.txtを読み込み、co-occurance.pngとして出力します)。
# 必要なモジュールのインポート(上記の再掲)
from pathlib import Path
import collections
import MeCab
import neologdn
import unicodedata
import networkx as nx
import matplotlib.pyplot as plt
from itertools import combinations, dropwhile
from collections import Counter, OrderedDict
import numpy as np
from networkx.drawing import nx_agraph
data_dir_path = Path('data')
stopword_list = ['|','で','た','ある','よう','ない', 'かた', 'ため', 'き','それ','なく','じゃ','わい','う','の','だ','な','れ','ず','さっき','これ','事','一','人']
# "stopword_list="によって、インデックスしない単語を指定
# TEXTファイルやCSVファイルを読み込むのが一般的だが、今回はわかりやすさのために直接指定している
# 実行ディレクトリのdataフォルダにあるrashomon.txtを読み込む
with open(data_dir_path.joinpath('rashomon.txt'), 'r', encoding='utf-8') as file:
lines = file.readlines()
# -----------------------------------------------------------------
# 分かち書きを行う(辞書ディレクトリはご自身のディレクトリを指定ください)
mecabTagger = MeCab.Tagger("anaconda3\envs\downgrade\lib\site-packages\ipadic\dicdir -Ochasen")
select_conditions = ['動詞', '形容詞', '名詞','副詞', '助動詞','感動詞']
noun_sentences = []
for sentence in lines:
words = []
sentence = neologdn.normalize(sentence)
sentence = unicodedata.normalize("NFKC", sentence)
node = mecabTagger.parseToNode(sentence).next
while node:
word = node.surface
pos1 = node.feature.split(',')[0]
pos2 = node.feature.split(',')[1]
pos3 = node.feature.split(',')[2]
if pos1 in select_conditions and word not in stopword_list:
if not (pos1 in "動詞" and pos2 in "非自立"):
words.append(node.surface) # 単語
node = node.next
noun_sentences.append(words)
# -----------------------------------------------------------------
# jaccard係数を計算する(jaccard係数:0.12以上、章跨ぎ単語登場数:4以上)
jaccard_coef = []
edge_th=0.12
pair_all = []
min_cnt=4
print('共起ネットワーク用単語ペア')
for chapter in noun_sentences:
pair_temp = list(combinations(set(chapter), 2))
for i,pair in enumerate(pair_temp):
pair_temp[i] = tuple(sorted(pair))
pair_all += pair_temp
pair_count = Counter(pair_all)
for key, count in dropwhile(lambda key_count: key_count[1] >= min_cnt, pair_count.most_common()):
del pair_count[key]
word_count = Counter()
for chapter in noun_sentences:
word_count += Counter(set(chapter))
for pair, cnt in pair_count.items():
jaccard_coef.append(cnt / (word_count[pair[0]] + word_count[pair[1]] - cnt))
print('単語ペア', '出現数', 'jaccard係数', '単語1出現数', '単語2出現数', sep='\t')
jaccard_dict = OrderedDict()
for (pair, cnt), coef in zip(pair_count.items(), jaccard_coef):
if coef >= edge_th:
jaccard_dict[pair] = coef
print(pair, cnt, coef, word_count[pair[0]], word_count[pair[1]], sep='\t')
# -----------------------------------------------------------------
# 共起ネットワークを作成する
G = nx.Graph()
nodes = sorted(set([j for pair in jaccard_dict.keys() for j in pair]))
G.add_nodes_from(nodes)
print('Number of nodes=', G.number_of_nodes())
for pair, coef in jaccard_dict.items():
G.add_edge(pair[0], pair[1], weight=coef)
print('Number of edges=', G.number_of_edges())
plt.figure(figsize=(15, 15))
seed = 0
np.random.seed(seed)
pos = nx_agraph.graphviz_layout(G, prog='neato', args='-Goverlap="scalexy" -Gsep="+6" -Gnodesep=0.8 -Gsplines="polyline" -GpackMode="graph" -Gstart={}'.format(seed))
pr = nx.pagerank(G)
nx.draw_networkx_nodes(G, pos, node_color=list(pr.values()), cmap=plt.cm.rainbow, alpha=0.7, node_size=[100000*v for v in pr.values()])
nx.draw_networkx_labels(G, pos, font_family='MS Gothic', font_weight='bold')
edge_width = [d['weight'] * 8 for (u, v, d) in G.edges(data=True)]
nx.draw_networkx_edges(G, pos, alpha=0.7, edge_color='darkgrey', width=edge_width)
plt.axis('off')
plt.tight_layout()
plt.savefig('co-occurance.png', bbox_inches='tight')
上手くいくと以下のような共起ネットワークが出力されます。

Pythonで描いた共起ネットワークとKH Coder版との違い
上記の図では筆者の環境のMeCabを使って実行しています。
したがって、筆者環境の辞書で分かち書き(単語に分解)が実行されるため、KH Coderでの共起ネットワーク描画とは異なり、"上"という単語が上位に登場しております。
これは、分かち書きの際に、”上る”と分解するか、”上”、”る”と分解するかの違いなどによって生じた結果です。
また、KH Coderではサブグラフへの分解を標準としています。一方でPythonではサブグラフに分けず、1つのグラフで表現をしています。したがって、両者の共起ネットワークは少し見え方が異なるかもしれません。
しかしながら、"下人"や"老婆"や"羅生門"等のワードは上位に登場しており、集計方法はJaccard係数(その中でも単語ペアが各Chapterでどれだけ登場したか)は共通です。
アウトプットのチューニング
KH Coderと同様に、最小出現数はmin_cnt=4の部分を変更、jaccard係数の下限(上位60などと同等)はedge_th=0.12の部分を操作することで、グラフの粒度を変更することができます。
また、余分に検知されてしまっている単語は、Stopwordのリストに追記することで除外することができます。
コラム|MeCabによる複合語抽出と代替方法
KH CoderもPythonも、形態素解析においてはMeCabを使用しています。
MeCab自体はとても優れているのですが、当然ながら知っている単語には限界があります。
本当はひとつながりの単語(複合語)なのに、分割されてしまって、共起ネットワークの描画において違和感を覚えるケースもあるでしょう。
そんなときは、KH Coder・Pythonともに何らかの方法を用いて、強制的に複合語抽出をおこなう必要があります。
KH Coderにおける複合語抽出
ますKHcoderの場合です。辞書機能や複合語の検出機能を利用すると、複合語をひとつの単語として抽出できます。
KH Coderのメニューから「前処理」「複合語の検出」「Use TermExtract」を選択することで、データ中の複合語を識別することができます。当然ながら、自動抽出なので抽出できない複合語も多く存在する点に注意が必要です。
Pythonにおける複合語抽出
また、Pythonの場合も同様です。複合語として抽出したい単語は、MeCabの辞書に登録しておけば、1つの単語として認識し、処理することができます。ただし、KHCoderと同様、短い文章の場合のみ可能です。
長い文の場合、登録する単語をひとつひとつピックアップするのは非現実的でしょう。
Pythonでは、termextractを使って文章から自動的に複合語を抽出することができます。ぜひお試しください!
まとめ|KH CoderやPythonで共起ネットワーク描画にチャレンジしてみよう
今回は、KH CoderというフリーソフトとPythonを使ったサンプルプログラムで、同じテキストデータを題材に共起ネットワークを作成しました。
文章を単語に分解(分かち書き)し、単語同士が一緒に登場する頻度をもとにJaccard係数を算出し、章ごとに集計することで、どのような単語の組み合わせが多く登場するのかが視覚的に表現できるようになりました。
また、その解釈の方法についても理解できたのではないでしょうか。
テキストマイニングの手法を用いることで、読んでいない文学作品であっても、
- どんなテーマで話が進んでいるのか
- 主役や主要登場人物は誰か
- 各章ではどんな話題が展開されているのか
がキーワードベースで視覚的に理解できるようになります。
今回は青空文庫を使いましたが、新聞記事やTweetなどのSNS投稿、アンケートの回答にテキストマイニングを適用すれば、特定のクラスタや時期におけるトレンドを知ることもできます。
過去は精度が悪かった日本語テキストマイニング、現在かなり進歩しており、また、十分実用に耐えうる分析が無料で実行できるようになっております。対応分析(コレスポンデンス分析)を通じて、テキストの特徴を知るなどの応用も可能です。
まずは身近なテキストデータをもとに共起ネットワークを作成してみてください!
KHCoder 初心者は必読!
開発者による公式入門書
動かして学ぶ! はじめてのテキストマイニング: フリー・ソフトウェアを用いた自由記述の計量テキスト分析 KH Coder オフィシャルブック II (KH Coder OFFICIAL BOOK 2)
KHCoderを使いこなしたい!
中上級者を目指す方はこちらも
社会調査のための計量テキスト分析―内容分析の継承と発展を目指して【第2版】 KH Coder オフィシャルブック 単行本 – 2020/4/6
▼テキストマイニングの全体像についておさえたい方は、こちらもあわせてご覧ください
▼PythonとWord2Vecを組み合わせて、単語や文章の類似度計算をしてみる


{kind=link}