
「テキストマイニング(計量テキスト分析)」とは、膨大なテキストデータを分析・定量化・視覚化する手法です。
テキストデータと聞くと身構えてしまうかもしれませんが、私たちは普段の生活でも多くのテキストデータに触れています。
例えば、プライベートではLINEでのやりとりやSNSやブログへの投稿がわかりやすい例でしょう。
ビジネスシーンでは、チャットや電子メール、コールセンター・コンタクトセンターへの問い合わせ記録、アンケート調査の結果など、多くのやりとりがテキストデータとして蓄積されています。
このようなデータを趣味や業務に生かすために「テキストマイニング」をやってみたい、お客さまの声に基づいた製品開発・サービスデザインをおこないたい、そう考える人も少なくないでしょう。
この記事では、テキストマイニングの基礎知識や活用事例、無料で使える分析ツールの紹介まで、明日からテキストマイニングをおこなうための土台となる内容をお伝えしていきます。
読み終わったらすぐに手を動かして試せるサービスもご紹介していますので、ぜひ最後までご覧ください。
KHCoder 初心者は必読!
開発者による公式入門書

動かして学ぶ! はじめてのテキストマイニング: フリー・ソフトウェアを用いた自由記述の計量テキスト分析 KH Coder オフィシャルブック II (KH Coder OFFICIAL BOOK 2)
KHCoderを使いこなしたい!
中上級者を目指す方はこちらも

社会調査のための計量テキスト分析―内容分析の継承と発展を目指して【第2版】 KH Coder オフィシャルブック 単行本 – 2020/4/6

テキストマイニングは文章を分析して定量化・可視化する手法
テキストマイニングは、膨大なテキストデータを分析し、定量化・視覚化する手法です。
テキストマイニングは計量テキスト分析と呼ばれることもありますが、この記事ではテキストマイニングに統一して話を進めます。
以下、少し難しい単語が出てくるので、アウトプットイメージを先にご覧いただきます。
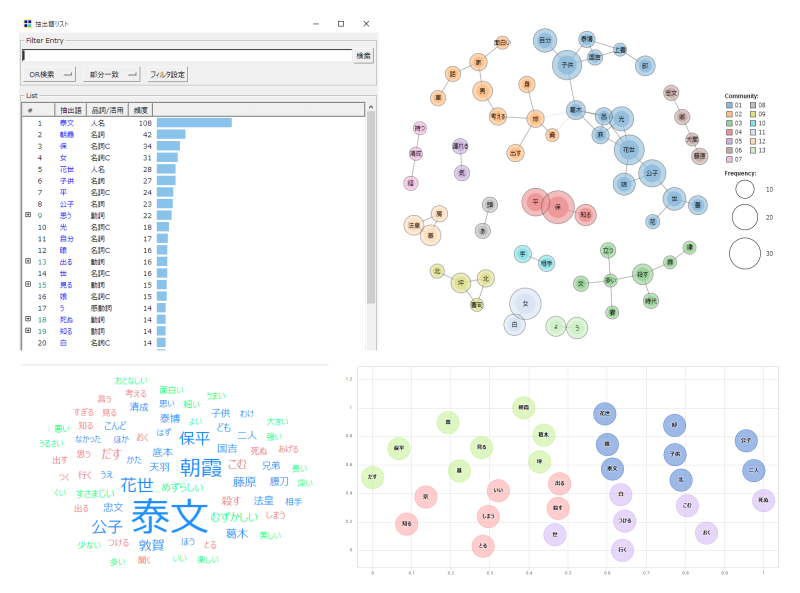
データソース|青空文庫
この例は、青空文庫にアップされている小説を分析して可視化したものです。
文章だけではとらえづらかった特徴(単語同士のつながりや頻出単語など)が、目で見てわかるようなかたちにアウトプットされている、と思っていただければ十分です。
以下、初学者にとっては少し込み入った話をするので、興味があるトピックまでスクロールしていただくのが良いでしょう。
テキストデータは特定の構造を持たないため「非構造化データ」と呼ばれます。
「非構造化データ」の反対語は「構造化データ」です。特定の構造を持ち、分析可能なかたちになったデータです。
つまり、テキストデータを分析するには「非構造化データ」を「構造化データ」に変換する必要があります。この変換時に「自然言語処理」という手法を用います。
このテキストマイニング、データマイニングから派生した分析手法です。そもそも、マイニングとは「採掘」という意味を持つ言葉です。
先ほど述べたデータマイニングは「統計学、パターン認識、人工知能等のデータ解析の技法を大量のデータに網羅的に適用することで知識を取り出すこと」を指します。
テキストマイニングは、その対象領域がテキストデータに限定されたもの、と思ってください。
「大量のテキストデータから、有益な情報を探し出す方法」と考えてもよいでしょう。
次に、テキストマイニングの意義(目的・やる意味)についてお伝えします。

テキストマイニングの意義(目的・やる意味)
テキストマイニングの目的:テキストデータから新たな知見・洞察を得て、次のアクションにつなげる
テキストマイニングに限った話ではありませんが、分析の最重要目的は「分析を通じて新たな知見を得たり、洞察を深めたりすることを通じて、次のアクションを決定・実行すること」です。
これが頭から抜け落ちた状態で分析を進めると、分析を行うこと自体が目的となってしまうケースもあるので、注意が必要です。
テキストマイニングの意義1: テキストデータの分析時間を短縮できる
テキストデータの理解は時間がかかるものです。データによっては(例えば、アンケートの自由記述欄など)、読み下しづらいものも少なくないためです。
定性的な分析に際しては、ひとつひとつ丁寧に読むのも重要ですが、まずは概要・大勢を迅速につかみたいケースではテキストマイニングが有効です。
数千字程度の文章であれば、使われている単語やその使用回数、単語同士の関係性をほんの数秒で分析してくれるからです。
テキストマイニングの意義2: テキストデータをわかりやすい形にアウトプットできる
冒頭でもお見せしたとおり、テキストマイニングによってテキストデータを定量的・視覚的に示すことが可能です。
テキストデータにどんな傾向があるか、章や時期によって使われる単語に変化があるか、近接して使われがちな単語は何か、などはテキストデータのままでは把握しにくいでしょう。
一目見てわかる形に変換できれば、自分の理解はもちろん、分析対象データを初めて見る人にとっても理解しやすくなります。
テキストマイニングの活用事例
事例1: 文書のテキストマイニングによる景気予測
景気ウォッチャー調査のテキストデータについて、統計的言語処理と機械学習の手法を用いて、3つの分析をおこなった事例です。過去と比較して相対的に出現頻度の高い特徴語を明らかにし、景気変動要因を可視化するために、共起ネットワークを用いています。また、インフレ率の指標をテキストデータから構築したり、インフレ予測や、実測の原因分析などにも適用されています。
機械学習による景気分析 ―「景気ウォッチャー調査」のテキストマイニング―(内閣府)
テキストデータを利用した新しい景況感指標の開発と応用(上) ― 入門編:基礎的概念と分析手法の解説 ―
事例2: 口コミ・ユーザーレビューのテキストマイニングによる商品開発戦略策定や企業評価
人間の思決定において、ネット上に書き込まれたレビューは強い影響力を持ちます。
たとえば、Amazonや楽天などで商品を購入する際に、星がいくつでどんな評価を下されているかを見たことがある人は多いでしょう。カスタマーレビューは多くの場合、総合評価や機能別評価、テキストデータであるクチコミコメントで構成されています。スコア評価とテキストマイニングで分析したレビューデータを用いて、評価項目にない箇所への満足・不満を可視化し、製品の改善・新商品開発のアイデア発想に生かしているケースもあります。
また、従業員・退職者によるクチコミ・レビューサイトのテキスト情報から、仕事のやりがいや働きやすさの代替指標を生成し、企業業績との関係を分析した事例もあります。
事例3: SNSの投稿(Twitterのツイート)のテキストマイニングによる感情分析
SNSではいまこの瞬間も多くの投稿がなされています。Twitterのツイートを思い浮かべていただくと、喜怒哀楽などの感情を伴った投稿も多く見られることは想像に難くないでしょう。SNSの投稿にはユーザーの心理・行動を理解するヒントが多く隠されているのです。
Twitterの投稿をテキストマイニングすることで、たとえば感情と購買行動の関連性や、炎上につながりうる表現の理解、特定の単語をつぶやくユーザーの潜在ニーズ発見など、さまざまな洞察が得られます。
Twitterの投稿データは、個人でも簡単に取得できるのでぜひ試してみてください。
「暇」ツイートのテキストマイニングによる潜在的ニーズの発見法に関する一考察
KHCoder 初心者は必読!
開発者による公式入門書
動かして学ぶ! はじめてのテキストマイニング: フリー・ソフトウェアを用いた自由記述の計量テキスト分析 KH Coder オフィシャルブック II (KH Coder OFFICIAL BOOK 2)
KHCoderを使いこなしたい!
中上級者を目指す方はこちらも
社会調査のための計量テキスト分析―内容分析の継承と発展を目指して【第2版】 KH Coder オフィシャルブック 単行本 – 2020/4/6
テキストマイニングの分析対象となるデータ
さて、テキストマイニングによる分析に関するお話に進みましょう。
まずはデータ様式について簡単にお話します。大きくわけて次の3つが挙げられます。
- 非構造化データ
- 構造化データ
- 半構造化データ
冒頭で簡単に触れたこれらのデータ、それぞれについて一言ずつコメントを記載します。
非構造化データ(=テキストマイニングに用いるデータは概ねこの形式)
非構造化データは、ネイティブな形式で保存された異なる種類のデータの集合体です。後述する構造化データとは違い、特定の構造を持ちません。例えば、音声・文章・動画・メール・文書などのデータが典型例に挙げられます。
例示した項目を見ると分かるように、テキストマイニングの分析対象となるデータばかりですね。
非構造化データは、簡単に定量的判断ができない、特定のルールに則って処理し(自然言語処理)、構造化データへ変換する必要があるのです。
構造化データ(=テキストマイニングの過程でこのかたちに変換される)
構造化データは、その名のとおり「構造化」されたデータです。データの形式などが特定のルールに従っているため、分析に使いやすいかたちになっています。
いわゆるデータベースに格納されているようなデータは、構造化データに分類されると考えて良いでしょう。もう少し身近な例でいうと、Excelファイルやを想像してみてください。行と列で規定され、各セルに格納されるデータの形式が決まっている、そういった状態のデータだと考えてください。
(参考)半構造化データ
半構造化データは、非構造化データと構造化データの橋渡しをするデータです。通常では非構造化データに分類されるデータのうち、何らかの特徴を際立たせるメタデータが含まれているものを指します。
テキストマイニングの分析手順
テキストマイニングを実際にやってみたくなってきた人も多いのではないでしょうか。
ここでは、テキストマイニングの大まかな手順についてのみ解説します。
詳しいやり方については、他の記事や成書をご参照ください。
- 手順1: 分析したいテキストデータを準備する
- 手順2: テキストデータを前処理・クレンジングする
- 手順3: テキストデータを形態素解析・分かち書きする
- 手順4: 単語を抽出・集計する
- 手順5: データを分析・可視化する
- 手順6: アウトプットをもとに考察・仮設立案・意思決定などをおこなう
テキストマイニングの分析手法の例
形態素解析(分かち書き)
形態素解析はテキストマイニングの第一歩目に相当する分析手法です。
テキストマイニングにおける形態素解析・分かち書きとは、文章を単語に分解することです。
例えば、以下の文章。
毎日、私は朝食として牛乳とパンを食べてから、出社します。
これを分かち書きすると、以下のように分解されます。
毎日 、 私 は 朝食 として 牛乳 と パン を 食べて から 、 出社 します 。
このように単語を品詞に分解すると、データとして扱いやすくなります。扱いやすくなる=計算がやりやすくなると考えて大丈夫です。
計算ができるようになると、単語同士の意味の近さや、文章間の類似度を算出することができるようになるのです。

共起分析・共起ネットワーク(コロケーション分析)
「共起」は単語がテキスト中に連続して出現することを指します。すなわち、「共起分析」はテキスト中に出現する単語間の連続性・関係性を分析する手法です。
また、「コロケーション」とは複数の単語同士の結びつきを意味します。したがって、「コロケーション分析」を簡単に言うならば、単語同士が連続したつながりを持ち、文法的に一定のまとまりがあるかどうか分析する手法です。
「共起ネットワーク」はこういった単語同士の結びつきやテキスト中におけるまとまりを視覚的に表現したものです(下図参照)。
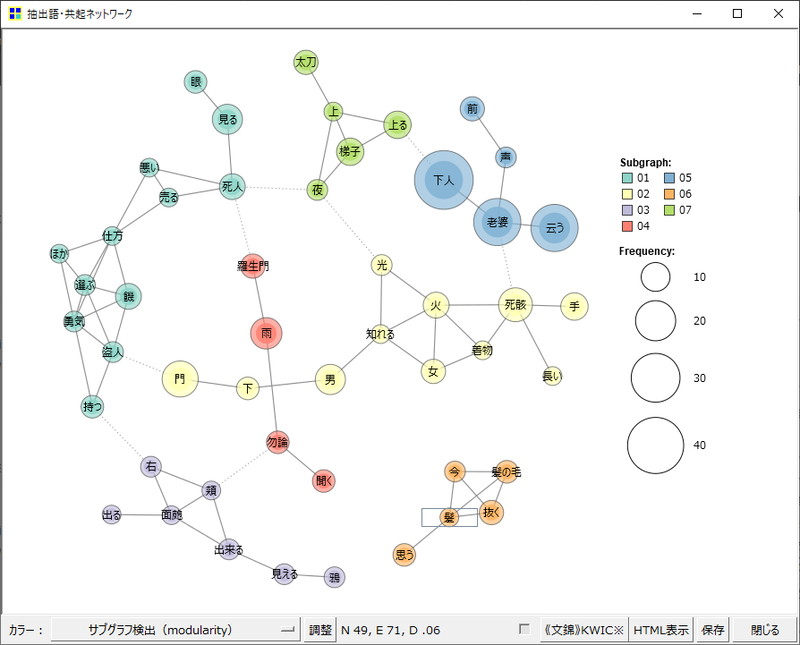
その視覚的な分かりやすさから大変人気がある手法です。

クラスター分析
データ群Aとデータ群Bのように異なるデータの集合同士の類似度を求めるために使用されるのがクラスター分析です。
大まかに分類すると、クラスター分析は
- 階層的クラスター分析
- 非階層的クラスター分析
に分類されます。
階層的クラスター分析
階層型クラスター分析とは、類似性または非類似性(距離)に基づいて、最も似ている単語を順次集めてクラスターを作成する方法です。アウトプットイメージは以下のとおり、樹形図として示されます。トーナメント表のようなこの樹形図はデンドログラムとも呼ばれます。
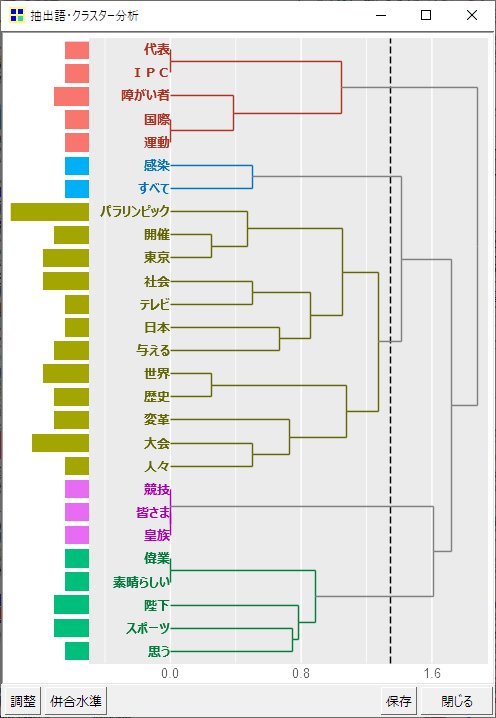
末端部は「葉」と呼ばれ、これらの葉と葉の距離が近いほど(トーナメント表的な見方をするなら、すぐに対戦する者同士、といったイメージ)似た者同士の単語と考えて良いです。
非階層的クラスター分析
似た者同士を順次まとめ上げる階層的クラスターとは異なり、非階層的クラスター分析では、最終的なクラスター数をあらかじめ決めます。その上で、自動的にグループ分けを行うのです。階層構造に分類できない複雑なデータセットに対して有効な手段です。
この非階層的クラスター分析の代表的手法が「k-means法」です。「k-means法」では、分析者があらかじめクラスター数を定義しておき、その数に着地するようにデータを分割していきます。その際、各データとクラスターの重心の距離が、別のクラスターの重心よりも近くなるよう、データを逐次再配置していきます。
感情分析(センチメント分析)
感情分析(センチメント分析)とは、SNSの投稿や口コミ・レビューデータなどのテキストデータを分析し、その文中に潜む感情をあぶり出す手法です。ポジティブ、中立、ネガティブなどに分類することで、ユーザー心理を読み解くことが可能になります。
感情をデータ化して可視化できれば、以下のようなことが直感的にわかるようになります。
- 特定のトピックスに対する世論がわかる
- 自社の商品・サービスの評判やブランドイメージがわかる
- 競合他社が高評価を博している施策を読み解ける
- ユーザーの不満をいち早くキャッチして改善活動に生かせる
特にTwitterのデータは感情の宝庫です。世の中のニュースや日々の出来事に対して、ユーザーは気軽に感情を伴った投稿が可能なためです。
単純に分析・可視化するだけでも多くの情報が得られますが、感情データを機械学習することで多様なサービス展開に応用することも可能です。

主成分分析・コレスポンデンス分析(対応分析)
コレスポンデンス分析(対応分析)は、簡単に言うと「単語間の関係性を、散布図と呼ばれるグラフで視覚的に表現する方法」のことです。
たとえば、ネットニュースを思い浮かべてください。多くのニュースサイトに出現する単語は原点近くに配置され、特定のニュースサイトに偏って出現する単語は原点から離れた場所に配置されます。また、互いに関連の強い単語は、原点から同じ方向に配置されます。
また、アンケート回答結果のようなデータでは、「回答者のセグメント(属性)×回答内容の特徴」を散布図として表現することが可能です。以下は「本記事の目標」で示したグラフの再掲ですが、単語(好きな車の情報。今回はメーカー名)がセグメント(年代)でどういった位置関係にあるかを知ることができます。

主成分分析とコレスポンデンス分析の違い
統計に精通している人は「主成分分析も同じような分析では?」と思ったかもしれません。
簡単に答えるなら、「両者は同じような分析」です。
もう少し詳しく言うと、コレスポンデンス分析(対応分析)は、「データ構造の再現は主成分分析に劣る」ものの、「特徴の表現においては良い結果を示す」ことが多いと言われています。
つまり、主成分分析は厳密な分析(情報を圧縮して再現)で、コレスポンデンス分析は情報をわかりやすい形で表現するといった形です。
全ての情報を表現したいなら主成分分析で、関係性を探りたいレベルであればコレスポンデンス分析の方が向いている形になります。
多変量解析の数量化Ⅲ類とコレスポンデンス分析の違い
コレスポンデンス分析(対応分析)も、多変量解析の数量化Ⅲ類も、多くの変数をまとめることができる分析方法です。
大まかに言うと、両者の分析ロジックには違いがありません。
少し細かく言うと、分析に用いる変数が0と1で構成される場合は定量化Ⅲ類、クロス集計表のようなデータの場合はコレスポンデンス分析(対応分析)と考えていただければ十分です。

KHCoder 初心者は必読!
開発者による公式入門書
動かして学ぶ! はじめてのテキストマイニング: フリー・ソフトウェアを用いた自由記述の計量テキスト分析 KH Coder オフィシャルブック II (KH Coder OFFICIAL BOOK 2)
KHCoderを使いこなしたい!
中上級者を目指す方はこちらも
社会調査のための計量テキスト分析―内容分析の継承と発展を目指して【第2版】 KH Coder オフィシャルブック 単行本 – 2020/4/6
テキストマイニングができるツール5選
「テキストマイニングツールにはどのような種類があるのだろう?」
「どのツールを使えば、どんなことができるのだろう?」
ここまで読み進めてきた人は、具体的なツールにも興味を持っているのではないでしょうか。ここからは、無料で使えるテキストマイニングツールをご紹介します。
AIテキストマイニングツール by ユーザーローカル
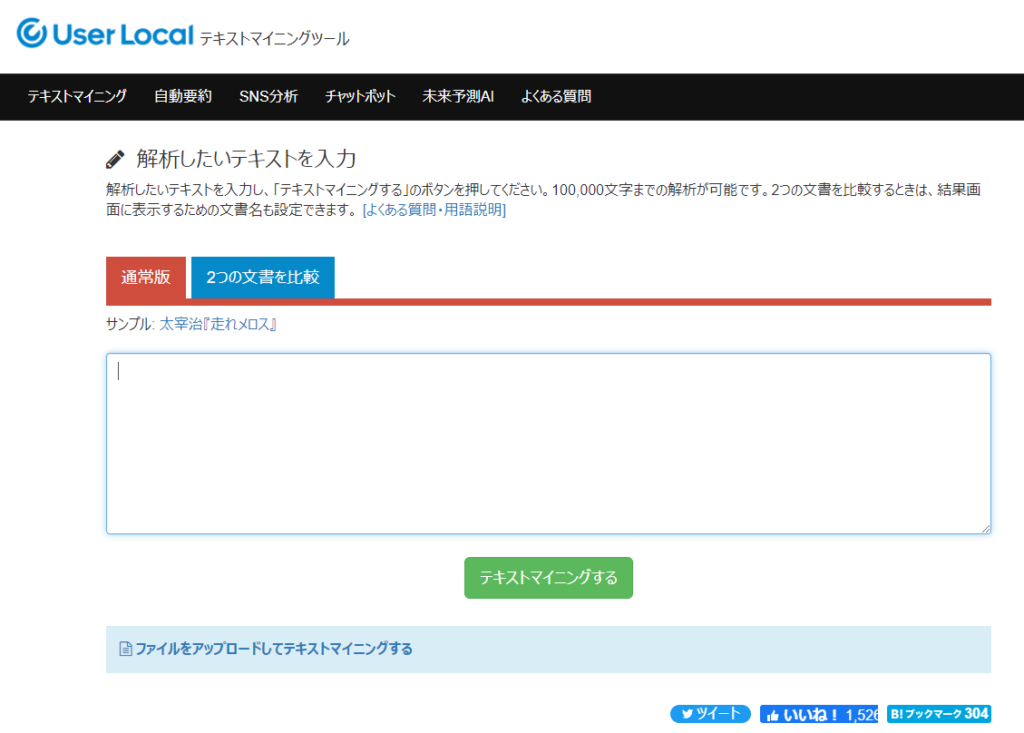
株式会社ユーザーローカルが提供するテキストマイニングツールです。ブラウザ上で利用することができます。インストールなどの環境設定が不要なので、「とにかくテキストマイニングを試してみたい!」という人にはイチオシです。
サイトにアクセスし、分析したいテキストをコピペするか、ファイルをアップロードするだけで分析を始められます。前処理から分析・可視化までが1クリックで実行可能です。何より、無料で使えるのがうれしいポイントですね。品詞別の頻出単語はもちろん、共起ネットワークやクラスター分析の結果も表示してくれます。
分析結果は論文などにも使用できるようです。詳しい注意点は、ユーザーローカルのWebサイトのFAQをご確認ください。
KH Coder
立命館大学 教授の樋口耕一氏が開発したテキストマイニングツールです。初心者から上級者、プライベートユースからビジネス・アカデミックユースまで、幅広いユーザー層を満足させてくれます。
KH Coderの解析には、「R」を利用して統計計算や可視化をおこなっています。
基礎的な分析であれば、ボタンクリックだけで前処理~分析・可視化を終えられるので、「R」について全く分からない人も安心して使えます。
テキスト中に頻出する単語の数やつながり(共起ネットワーク)や、同じ単語を含むテキストのグループから、テキストの特徴を分析(コレスポンデンス分析)することができます。
ソースコードが公開されているためカスタマイズ性がある点も特徴です。
Exploratory
Exploratoryは、データを「探索」することに優れた分析ツールです。
RやPythonでは解析を行うためにコードを書く必要がありますが、Exploratoryはいわゆる「ノーコード」のツールなのでプログラミング言語が分からなくても大丈夫(裏側ではR言語が動いています)。
データを用意して読み込んで、アナリティクスボタンをクリックするだけで、以下のようなさまざまな分析を行うことができます。
相関
K-Meansクラスタリング
主成分分析(PCA)
線形回帰
ロジスティック回帰
一般化線形モデル
決定木
ランダムフォレスト
生存曲線
コックス回帰
ランダム・サバイバル・フォレスト
時系列予測
異常値検知
マーケット・バスケット分析
統計的検定
A/Bテスト-ベイジアン など
このExploratory 、Excelや各種データベースなどさまざまなソースからデータを取得することができます。取得したデータはワンクリックとはいかないものの、数ステップで簡単に分析・ワードクラウド化することができます。
自由記述アンケートのテキスト分析 Part 1:文章の単語化とワードクラウドを使った可視化
安倍首相に関するTwitterデータをテキストマイニングして可視化 - RMeCab使う版
公式のコンテンツとして、Exploratoryで主成分分析を実行する方法を解説してくれているので、ぜひご覧ください。
プログラミング言語(R / Python)
PythonやRなどのプログラミング言語には、統計解析や機械学習においておなじみのプログラミング言語ですが、テキストマイニングのためのライブラリももちろん用意されています。
「ライブラリ」とは、特定の目的のための関数を集めた「パッケージ」の総称のことです。「パッケージ」は、「モジュール」を複数集めたもののことであり、「モジュール」は複数の関数を集めたもののことを指します。RもPythonも、データ分析に使われる機械学習法や統計解析周りのライブラリが揃っています。Pythonには深層学習を実装するためのライブラリが多数用意されており、こういった点はRとの差別化要因です。
RやPythonは、なんといっても無料で実行できるのが魅力です。また、RやPythonは多くの人が利用しているため情報の検索がしやすいのも大きなメリットです。
一方で、ソースコードの修正やコマンドラインからの操作は複雑で、必ずしも初心者向けではなく、使いこなすにはそれなりの時間と労力が必要になります。
Excel
これまでご紹介してきた高度なテキストマイニングツールやプログラミング言語に比べると、Excelによるテキストマイニングには制約が多くあります。
しかし、ごく基本的な機能を用いて、Excelをテキストマイニングツールとして使用することは可能です。何らかのテキストを文章→段落→文節→単語と細分化し、単語の出現回数を集計することで頻出する単語を把握するなどできます。
頻出語さえ集計できてしまえば、オープンソースのデータビジュアライゼーションプラットホーム 「E2D3(Excel to D3.js)」によってワードクラウド化ができたのですが、残念ながら2021年8月31をもってサービス終了となりました。
他にもExcelTTMなど、Excel上で動作するテキストマイニングの処理ツールがあるので、Excelでテキストマイニングをしてみたい人は試してみると良いでしょう。
テキストマイニングツールの選び方のポイント
テキストマイニングに使えるツールをいくつかご紹介指摘ましたが、最終的な判断基準がわからず困っていませんか?選び方のポイントを以下に示します。
使いやすいUI(ユーザーインターフェース)かどうか
どんなに優れたツールでも、使いこなせなければ意味がありません。テキストマイニングを使用した分析では、ツール内を行ったり来たりするケースが少なくありません。したがって、使いやすいUI(ユーザーインターフェース)のツールを選択すると良いでしょう。
元データの参照が簡単にできるか
テキストマイニングではツール内を行ったり来たりする、とお伝えしました。分析結果で出現回数が上位だった単語に着目するシーンを想像してください。注目したい単語を、膨大なテキストデータの中から探し出す。これは現実的でしょうか?いくらじかんがあっても足りないでしょう。
定量的に解きほぐすだけが分析ではありません。定性的に、どんな文脈でその言葉が使われているのかをとらえるためには、簡単に元データを参照できることが非常に重要なのです。
エクスポート機能が使えるか、使いやすいか出力機能は豊富か
データをグラフや表などの視覚的にわかりやすい状態で出力できる機能があるかどうかも重要です。テキストマイニングで得た知見を報告する際に必要になります。
また、データを表やグラフのようなかたちに視覚的に理解しやすいかたちでエクスポートできることも重要です。これは、自身の理解のためにも必要ですし、組織内での結果報告においても必要です。任意の色や形にカスタマイズできると、たとえばコーポレートカラーに準ずるかたちでアウトプットできます。エクスポートの形式やカスタマイズ性にも目を向けてみましょう。
処理速度は早いか
処理速度がどのくらいになるかは、実際に触ってみないとわからないことが多いです。ローカルで処理する場合は、ある程度のマシンスペックが要求されるケースも少なくありません。今回紹介したツールはいずれも無料で使えるものばかりでしたが、有償版を使用する際は導入前にトライアルさせてもらうのが良いでしょう。
分析精度が満足できるレベル感か
テキストマイニングツールのもっとも基本的な機能は分析です。自身のニーズに合った精度の分析ができるツールを選びましょう。とりあえず雰囲気をつかめれば良いだけなら高精度なツールは不要ですし、精緻な分析が必要なのであれば高精度でカスタマイズ性の高いツールを使う方が良いでしょう。
テキストマイニングの勉強におすすめの本
テキストマイニングに関しては良書が多く存在します。プログラミング言語やツール別に執筆されているケースが多いため、以下ではR・Python・KH Coderでテキストマイニングをおこなう際に参照したい書籍を列挙します。入門レベル~中級レベルを中心にピックアップしています。
各書籍の詳細は別途記事を準備して解説いたします。
Rでテキストマイニングしたいときにオススメの本
Pyhyonでテキストマイニングしたいときにオススメの本
- 言語研究のためのプログラミング入門: Pythonを活用したテキスト処理
- コピペで簡単実行!キテレツおもしろ自然言語処理 PythonとColaboratoryで身につく基礎の基礎
- 自然言語処理〔改訂版〕 (放送大学教材)
- 機械学習・深層学習による自然言語処理入門 ~scikit-learnとTensorFlowを使った実践プログラミング~ (Compass Data Science)
KH Coderでテキストマイニングしたいときにオススメの本
- テキストマイニング入門: ExcelとKH Coderでわかるデータ分析
- 動かして学ぶ! はじめてのテキストマイニング: フリー・ソフトウェアを用いた自由記述の計量テキスト分析 KH Coder オフィシャルブック II
- 社会調査のための計量テキスト分析―内容分析の継承と発展を目指して【第2版】 KH Coder オフィシャルブック
テキストマイニングまとめ
この記事では、テキストマイニングの基礎知識や事例、無料で使える分析ツールの紹介まで、幅広くお伝えしてきました。まずは無料で使えるツールから、テキストマイニングの世界に足を踏み入れてみましょう。

」とは、膨大なテキストデータを分析・定量化・視覚化する手法です。 テキストデータと聞くと身構えてしまうかもしれませんが、私たちは普段の生活でも多くのテキスト){kind=link}