
文章の解析を行うために、類似度の判定などを扱う一般的な方法として、Word2Vecと呼ばれるテキストマイニングの手法があります。Word2Vecは2013年にGoogleが開発した手法です。

Word2Vecによるテキストマイニングは、言葉をベクトル(向き)で表現するため、向きの近さ(角度の小ささ)を見たり、向きの重ね合わせ(角度の変更)ができます。
▼向きの重ね合わせイメージ(足し算)
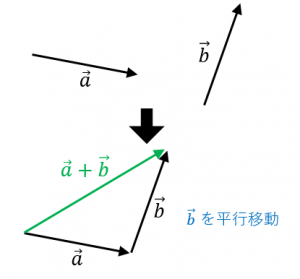
この記事では、PythonとWord2vecのmodel作成、学習済modelの活用という2つのパターンをベースに、類似度を見る方法、さらにwordnetを使った類語検索について紹介します!
KHCoder 初心者は必読!
開発者による公式入門書

動かして学ぶ! はじめてのテキストマイニング: フリー・ソフトウェアを用いた自由記述の計量テキスト分析 KH Coder オフィシャルブック II (KH Coder OFFICIAL BOOK 2)
KHCoderを使いこなしたい!
中上級者を目指す方はこちらも

社会調査のための計量テキスト分析―内容分析の継承と発展を目指して【第2版】 KH Coder オフィシャルブック 単行本 – 2020/4/6
本記事のゴール|単語をWord2Vecで処理できるようになる!
難しそうに思われがちな単語の類語検索や単語の足し算引き算などの処理をPythonからWord2Vecを使って処理できることを目指します。
類語検索の例:正月で検索
正月 → 元旦、元日、正月、年始、新年、新春、お正月、お年始、年明け、年の初め、新しい年、年の最初
足し算引き算の例:王様から女王 (Word2Vecでよく使われる例です)
「King」―「Man」+「Woman」=「Queen」
※王様から男を引いて、女を足すと女王になるという意味です。

PythonでWord2Vecを使うための準備
今回はPythonのgensimというライブラリを用いてWord2Vecを使います。また、文章を単語に分解するためMeCabも利用します。
そのためpip install で以下のライブラリを入れてください。
- gensim
- mecab-python3
Word2Vecのモデル作成
PythonでWord2Vecのモデルを作るには以下のように作成します。
InputにするMeCabで形態素解析するファイルはWikipedia、Twitter、アンケート、コールセンターの対応ログ、小説などにすることが多いです
最初から作成するのは「面倒そう」と思われる方は、次に解説する「学習済みモデルの活用」に移って学習済みモデルを活用する方法を参照してください。
▼Word2Vec_model作成コード
from gensim.models import word2vec
sentences = word2vec.LineSentence('MeCabで形態素解析したテキストファイル名')
model = word2vec.Word2Vec(sentences,
sg=1,
size=100,
min_count=1,
window=10,
hs=1,
negative=0)
model.save('出力するモデル(xxx.model)')
Word2Vecのモデル利用
単語A(例えば、戦争)、単語B(例えば、怒り)を引いたときに、どのような意味が類語としてあがるのかといったことを確認できます。
▼Word2Vec_model利用コード
from gensim.models import word2vec
model = word2vec.Word2Vec.load('利用するModelのファイル名(.modelのfile)')
results = model.most_similar(positive=[u'単語A(戦争)'], negative=[u'単語B(怒り)'], topn=表示したい単語数)
for result in results:
print(result[0])
学習済みmodelの活用
前章で1からmodelを作成する方法を簡単に解説しましたが、準備に時間のかかる学習フェーズ(model作成の工程)をスキップし、学習済modelを活用する方法をご紹介します。今回、紹介するのは白ヤギコーポレーションのmodelとFacebook学習済みのFastText modelの2つです。
例1:白ヤギコーポレーションの学習済みモデルの活用
白ヤギコーポレーションの学習済みモデルは こちら からダウンロードできます。
ダウンロードできない場合は、こちら からダウンロードください
白ヤギのモデルは、mecab による分かち書きでWikipediaを使って学習したモデルです。 50次元のみ公開されています。ちなみに、modelを構築するためのビルド用ソースコードも こちら に公開されています。
モデルを利用するのは簡単で、以下のようにgensimで読み込み、後は普通のWord2Vecとして活用するだけです。
▼ShiroyagiCorp_model_load
from gensim.models.word2vec import Word2Vec
model = Word2Vec.load(word2vec.gensim.model)
例2:FastTextに学習済みモデルの活用
Facebookの学習済みFastTextモデルはこちらからダウンロードできます。
ダウンロードしたモデル(vectorフォルダのmodel.vec)は以下のように読み込みます。
▼Fasttext_model_load
import gensim
model = gensim.models.KeyedVectors.load_word2vec_format('model.vec', binary=False)
モデルを用いた類似度算出
読み込んだモデルで特定の単語の類義語検索を行う方法と文章の類似度測定方法の2つをご紹介します。
1:特定の単語の類義語を検索する
例えば、「講義」という単語の類義語を見つけたい場合は以下のように数行書くだけとなります。
▼model読込後に追記するコード
results = model.most_similar(positive=['講義'])
for result in results:
print(result)
実行結果は以下のように単語とコサイン類似度のセットが返ってきます(コサイン類似度の高い順に返ってきます)。
▼結果
('授業', 0.6795130968093872)
('講読', 0.6785069704055786)
('講演', 0.662272572517395)
('講話', 0.6550379991531372)
('聴講', 0.6494878530502319)
('講座', 0.6335989832878113)
('レクチャー', 0.6315985918045044)
('復習', 0.580752968788147)
('進講', 0.5763939619064331)
('大学院生', 0.5596680641174316)
2:文章間の類似度を判定する
単語の類義語を探すだけではなく、文章間の類似度を計算することもできます。以下は、文章を構成する単語のベクトル平均を文章のベクトルとみなして計算する方法です。
ベクトルの平均ではないやり方で文章のベクトルを判定する方法もあります
import MeCab
import numpy as np
tagger = MeCab.Tagger('')
# ベクトル平均を計算
def get_vector(text):
sum_vec = np.zeros(200)
word_count = 0
node = tagger.parseToNode(text)
while node:
fields = node.feature.split(",")
if fields[0] == '名詞' or fields[0] == '動詞':
sum_vec += model[node.surface]
word_count += 1
node = node.next
return sum_vec / word_count
text1 = get_vector('昨日、カレーを食べた。')
text2 = get_vector('昨夜、Netflixでお笑いを見た。')
sim = np.dot(text1, text2) / (np.linalg.norm(text1) * np.linalg.norm(text2))
print(sim)KHCoder 初心者は必読!
開発者による公式入門書
動かして学ぶ! はじめてのテキストマイニング: フリー・ソフトウェアを用いた自由記述の計量テキスト分析 KH Coder オフィシャルブック II (KH Coder OFFICIAL BOOK 2)
KHCoderを使いこなしたい!
中上級者を目指す方はこちらも
社会調査のための計量テキスト分析―内容分析の継承と発展を目指して【第2版】 KH Coder オフィシャルブック 単行本 – 2020/4/6
Wordnetの利用
WordNetは同義語・意味上の類似関係を分類した巨大な辞書(シソーラス。言葉を同義語や意味上の類似関係、包含関係などで分類した辞書)です。
Word2Vecのように自動で分類したり、演算出来るわけではないのですが、データベースをダウンロードし、そこにアクセスすることで「類義語」、「上位概念」、「下位概念」に該当する言葉を検索することができます。
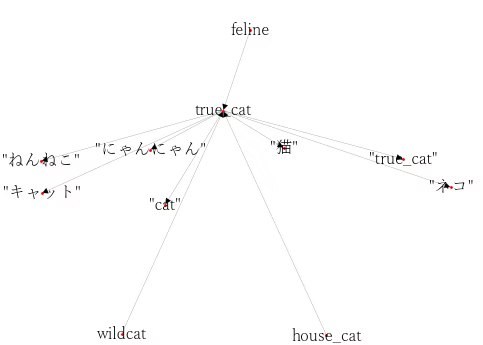
日本語版もありますが、本家のWordNet(英語)と日本語WordNetを照らし合わせると、違うところもあるので、日本語WordNetのデータ構造から中身を把握した方がよいと思います。
日本語WordNet - http://compling.hss.ntu.edu.sg/wnja/jpn/index.html
本家WordNet - https://wordnet.princeton.edu/
類義語の例
猫 → にゃんにゃん, キャット, ネコ
上位概念の例(猫)
猫の上位概念 → 動物
下位概念の例(動物)
動物の下位概念 → 犬, 猫, 猿
WordnetのDB定義
「word」, 「synset」, 「sense」, 「synlink」の4テーブルで構成されます
word:単語テーブル
- wordid : 単語ID(8桁の数字)
- lang : 言語 ('jpn'は日本語, 'eng'は英語)
- lemma : レンマ(文字列)
- pron : 読み方
synset:概念テーブル
- synset : 概念ID
- pos : 品詞ID(5: 形容詞、6: 副詞、7: 名詞、8: 動詞) ※1~4は英語
- src : ソース
sense:概念と単語の関連テーブル
- synset : 概念ID
- wordid : 単語ID
- lang : 言語 (jpn, eng)
- rank : ランク
- lexid : 不明(DBではengのみ1以上の値が入っている)
- freq : 頻度(DBではengのみ0以上の値が入っている)
- src : ソースだが、何に使われるのか不明
synlink:2つの概念の関係(上位・下位、包含・被包含など)のテーブルです。
- synset1 : 概念ID1
- synset2 : 概念ID2
- link : リンクID
- src : ソースだが、何に使われるのか不明
Wordnetの準備
DBとDBアクセスに必要なプログラム(wordnet_jp.py)をダウンロードし、Pythonの実行フォルダ(ユーザーフォルダなど)においてください。
WordnetDBのダウンロード
こちら にアクセスし、左メニューのリリース・ダウンロードのリンクを押し、Japanese Wordnet and English WordNet in an sqlite3 databaseのリンクからDBをダウンロードください。
wordnet_jp.pyのダウンロード
こちら をダウンロードください。
Wordnetの実行例
「楽しい」という単語が意味の集合に含まれる単語の一覧(同義語集合)を表示するプログラムです。
▼「楽しい」の類語検索プログラム
import wordnet_jp
word = '楽しい'
synonym = wordnet_jp.getSynonym(word)
print(synonym)
以下のような結果が返ってくれば正しく動作したことになります。
{
'gratifying': ['楽しい', '愉快', 'おもしろい', '悦ばしい', '満足', '心嬉しい', '痛快', '愉しい', '心うれしい', '面白い'],
'happy': ['うれしい', '愉しげ', '楽しい', '明るい', '仕合わせ', 'ご機嫌', '楽しげ', '悦ばしい', '御機嫌', 'ハッピー', '心嬉しい', '大喜び', '幸福', '幸せ', '喜ばしい', '仕合せ', '嬉しい', '心うれしい', '嬉々たる'],
'pleasant': ['愉しげ', '心地良い', '楽しい', 'よい', '好い', '快然たる', '愉快', '気持ち良い', '楽しげ', '快い', '麗しい', '快適', 'いい', '好いたらしい', '良い', '心地よい', '善い', '愉しい', '嬉しい', '心地好い'],
'good': ['楽しい'], 'merry': ['楽しい', '楽しげ', '賑やか', '面白い'],
'entertaining': ['可笑しい', '楽しい', '面白い'],
'delicious': ['楽しい', 'おもろい', '愉快', 'おもしろい', '悦ばしい', '小気味好い', '心嬉しい', '愉しい', '喜ばしい', '心うれしい', '小気味よい', '面白い']
}
まとめ
今回、Word2VecをPythonから呼び出し、modelを作成する方法、学習済みmodelを使って単語の類語検索をする方法、Wordnetを使う方法を紹介しました。
1からmodelを作成するのは大変と思われた方も、学習済みモデルを使うことで簡単に類語を探すなどができるようになったかと思います。
類語を使うことで、テキストマイニングをする際に、特定の単語に集約して分析することや、チャットボットの構築や感情分析の精度向上につなげるといったことが期待できます。
数行のコードを記載するだけで、簡単に対応することができると思います。ぜひ皆さまお試しください。
KHCoder 初心者は必読!
開発者による公式入門書
動かして学ぶ! はじめてのテキストマイニング: フリー・ソフトウェアを用いた自由記述の計量テキスト分析 KH Coder オフィシャルブック II (KH Coder OFFICIAL BOOK 2)
KHCoderを使いこなしたい!
中上級者を目指す方はこちらも
社会調査のための計量テキスト分析―内容分析の継承と発展を目指して【第2版】 KH Coder オフィシャルブック 単行本 – 2020/4/6
▼テキストマイニングの全体像についておさえたい方は、こちらもあわせてご覧ください
▼KH CoderとPython、それぞれで共起ネットワークを描写する方法について解説しています


{kind=link}